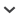We cloned cDNAs encoding two peroxins, PEX-1 and PEX-6, of the nematode Caenorhabditis elegans. Peroxins are proteins that play essential roles in peroxisome biogenesis and are encoded by pex genes. Among the peroxins, PEX-1 and PEX-6 constitute the subfamily 2 of AAA (ATPases associated with diverse cellular activities) proteins. Each cDNA agreed well with the respective mRNA in size (3.4 kb for pex-1 and 2.3 kb for pex-6) and did not carry any spliced leader sequence. The pex-1 cDNA was composed of 24 exons, which were encoded by a genomic region containing three open reading frames (ORFs), c11h1.4, c11h1.5, and c11h1.6; the predicted ORF c11h1.5 was encompassed in the 15th intron. Although many exon-intron borders in pex-1 were inconsistent with those predicted for c11h1.4 and c11h1.6, those in pex-6 coincided with those for the ORF f39g3.7. The pex-1 and pex-6 genes encoded proteins with 996 and 720 amino acid residues, respectively. Both pex-1 mRNA and pex-6 mRNA were detectable mainly in intestinal cells throughout the life cycle of C. elegans.
INTRODUCTION
Peroxins are proteins that play essential roles in peroxi-some biogenesis and are encoded by increasing numbers of pex genes (Distel et al., 1996). Among the peroxins, Pex1p (yeast protein)/PEX1 (mammalian protein) and Pex6p/PEX6 belong to the AAA (ATPases associated with diverse cellular activities) protein family (Erdmann et al., 1991; Kunau et al., 1993). Although no common biological function for AAA proteins has yet been elucidated, they share one or two copies of a conserved sequence of 200–250 amino acid residues, which is termed AAA cassette and encompasses the Walker motifs A and B for ATPases (Walker et al., 1982; Karata et al., 1999) and the second region of homology (SRH) (Swaffield et al., 1992; Karata et al., 1999). The AAA family is divided into 17 subfamilies according to the number of AAA cassettes, the extent of their sequence conservation, the function of the protein, and so on (Beyer, 1997). Subfamily 2 (SF2), which consists of only two members, Pex1p/PEX1 and Pex6p/PEX6, presents two AAA cassettes of which the one located closest to the C-terminus is highly conserved, while the other one diverges from the consensus sequence considerably. The two SF2 member proteins interact with each other in an ATP-dependent manner (Tamura et al., 1998; Faber et al., 1998), the overexpression of one suppresses the allele-specific defect of the other (Geisbrecht et al., 1998; Faber et al., 1998), and the interaction seems to be crucial for peroxisome biogenesis (Geisbrecht et al., 1998); the two proteins have been speculated to be involved in the fusion of pre-peroxisomal vesicles (Titorenko and Rachubinski, 2000).
The peroxisome biogenesis disorders (PBDs) are a group of lethal autosomal-recessive diseases caused by mutations in pex genes. Zellweger syndrome (ZS, alternatively called cerebro-hepato-renal syndrome) is the most severe PBD, which is classified into ten complementation groups (CGs). The genes PEX1 and PEX6 are responsible for CG1 (alternatively called CG-E) (Reuber et al., 1997; Portsteffen et al., 1997) and CG4 (or CG-C) (Tsukamoto et al., 1995; Yahraus et al., 1996), respectively. ZS is characterized by brain malformation that has been attributed to an impediment in gliophilic neuronal migration (Evrard et al., 1978). The principal effect of defective peroxisomes on neuronal cells could be studied with the Caenorhabditis elegans model, which has many biological advantages, especially it's fully established cell lineage (Schnabel and Priess, 1997), completed genomic sequence (The C. elegans Sequencing Consortium, 1998), and RNA-mediated interference (RNAi) for the analysis of gene function (Fire et al., 1998). Although C. elegans peroxisomes have been detected (Togo et al., 2000), none of the peroxins has yet been identified. Here, we report the cDNA cloning and expression of C. elegans genes encoding two putative peroxins that belong to SF2, designated as pex-1 and pex-6.
MATERIALS AND METHODS
Organisms and cDNA library
The Bristol N2 strain of C. elegans was used throughout this study according to the methods compiled by Lewis and Fleming (1995). Synchronized populations of the nematode were obtained as described (Maebuchi et al., 1999). C. elegans λ ZAPII cDNA library, made with poly(A)-rich RNA from the whole animal, was a generous gift from Dr. Alan Coulson (The Sanger Center, Cambridge, UK). Saccharomyces cerevisiae strain MB328 (MATa, his3, leu2, ura3, pex1) was isolated by the method of Erdmann et al. (1989) and identified as a pex1 mutant by genetic complementation analysis.
Cloning of the pex-1 cDNA
The primers S1 (sense, 5′-TCCCCCGGGGGAAGACGTCGGTGGAATGTTTG) and A1 (antisense, 5′-GCTCTAGAGGCTAACGTCACTTTCTGACCTATC) amplified an 808-bp sequence when the cDNA library was used as a template for polymerase chain reaction (PCR); the sequence corresponded to the open reading frame (ORF) c11h1.6. The product was cloned into the plasmid pUC119 (Takara) generating pEMB835 (Fig. 1A). The sequences extending to the 5′ and 3′ termini of the mRNA were obtained by RACE (rapid amplification of cDNA ends) (Frohman et al., 1988). Products amplified by two successive rounds of 5′ RACE were cloned into the plasmid pBluescript SK(−) (Stratagene) providing the plasmids pEMB838 and pEMB842. Primers used were as follows: S2 (5′-GACTCGAGTCGACATCGATTTTTTTTTTTTTTTTT), S3 (5′-GACTCGAGTCGACATC G), A2 (5′-CGGGATCCGCCAACGAATCCAGCTCATCAAAG), A3 (5′-AACTGCAGCACTG GCTCCAATATATTTCGAC), A4 (5′-CGGAATTCCTCCAACGGATTCGAAAAGTTG), A5 (5′-AACTGCAGGTCTCGAATATTTCACAACGG), A6 (5′-CGGGATCCCTCGGCTTCTTCA GTTCTTTTCCG), and A7 (5′-AACTGCAGCGGAACGACTTTCAAACGAATTGC). The 3′ untranslated region of the pex-1 cDNA was obtained by 3′ RACE with primers S4 (5′-GGGGAGCTCTGGGTAAAATCGAAGATGGACAAG), S1, and (dT)17, and cloned into pBluescript SK(−) generating the plasmid pEMB855. The probe P1 was prepared by PCR with the primers S1 and A4.
Fig. 1
Schematic structures of the composite cDNAs encoding PEX-1 (A) and PEX-6 (B). Thin lines indicate the cDNA clones (A: pEMB835, pEMB838, pEMB842, and pEMB855; B: pEMB732 and pEMB807) and thick lines indicate probes (A: P1; B: P2 and P3). The open box represents the ORF, in which bars show the first and second AAA cassettes (1 and 2), and the open rectangles denote the poly(A) sequence. Arrowheads mark positions of sequences corresponding to PCR primers. The nucleotides on the mRNA-identical strand are numbered; position +1 is A of the start codon of the ORF. The nucleotide sequences of pex-1 and pex-6 are available at DDBJ/EMBL/GenBank under the accession numbers AB054992 and AB010968, respectively.

Cloning of the pex-6 cDNA
A cDNA that carried the ORF f39g3.7 was obtained by screening the λZAPII cDNA library as described (Bun-ya et al., 1997) and cloned into pBluescript SK(−); the resulting plasmid was pEMB732 (Fig. 1B). The probe P2 used for screening was prepared by PCR with primers S5 (5′-GAAGAGTGCGAATGTGTTC) and A8 (5′-CCGATGAGTTTCAGAAG C). The 5′ region of pex-6 cDNA was amplified by 5′ RACE with primers S2, S3, A8, A9 (5′-CTCGGATCCGTGGTAATTGTGAAGGAGG), and A10 (5′-CTCGGATCCAGAATCCCT AGAGACCAACATG). The RACE product was identified with the probe P3 that was amplified with the primers S6 (5′-AATTGATTTATTCTACTTTGAGG) and A10, and the longest product was cloned into pBluescript SK(−) to generate the plasmid pEMB807.
Other methods
Cells of mixed-stage animals were disrupted by grinding in liquid nitrogen and the poly(A)-rich RNA was isolated using a μMACS mRNA isolation kit (Miltenyi Biotec). The pex-1 and pex-6 mRNA were detected by northern blot analysis with the antisense RNA probes, which were labeled with a digoxigenin-labeled nucleic acid detection kit (Boehringer Mannheim). The templates used for in vitro synthesis of the sense and antisense RNA probes were derivatives of pEMB842 and pEMB732; the derivatives carried the cDNA fragments of pex-1 (nucleotides +1 to +450) and pex-6 (nucleotides −70 to +305). The preparation of CeIF (C. elegans homolog of initiation factor A4) mRNA and the procedure of whole-mount in situ hybridization were performed as described (Maebuchi et al., 1999). TBLASTN searches of the C. elegans ACEDB database were run on the server at The Sanger Center ( http://www.sanger.ac.uk). The CLUSTAL W program (Thompson et al., 1994) was used for sequence alignments.
RESULTS
Composite cDNA encoding PEX-1 and PEX-6
We searched the C. elegans genome database for orthologs of SF2 proteins and found two open reading frames, c11h1.6 and f39g3.7, which encode polypeptides with the highest similarity to Pex1p/PEX1 and Pex6p/PEX6, respectively. Gene-specific probes were prepared by PCR amplification of a C. elegans cDNA library with appropriate primers: S1 and A1 for pex-1 (Fig. 1A) and S5 and A8 for pex-6 (Fig. 1B). Since c11h1.6 encodes only the region of the highly conserved AAA cassette, we applied the RACE procedure directly to isolate the 5′ and 3′ portions of the pex-1 cDNA. Three cDNA fragments cloned in pEMB842, pEMB838, and pEMB855 corresponded to the 5′ distal, central, and 3′ distal regions of the mRNA, respectively, and constituted a cDNA of 3391 nucleotides (nt) (Fig. 1A). The main body of pex-6 cDNA was obtained by plaque hybridization because the region encoded by f39g3.7 extended beyond the AAA cassette sequences. This clone, pEMB732, together with clone pEMB807 obtained by 5′ RACE constituted the cDNA of 2303 nt (Fig. 1B). The lengths of the pex-1 and pex-6 cDNA coincided well with those of mRNA detected by northern blot analysis of the poly(A)-rich RNA from a mixed-phase culture; 3.4 kb for pex-1 and 2.3 kb for pex-6 (Fig. 2). Therefore, we concluded that the composite cDNA corresponded to the respective full-length mRNA. No spliced leader (SL) sequence was detected at the 5′ end of either cDNA.
Fig. 2
Northern blot analysis. The poly(A)-rich RNA (about 5 μg) prepared from mixed-phase cultures was separated by electrophoresis in the presence of 2.2 M formaldehyde, transferred onto nylon membranes and probed with pex-1 (A) or pex-6 (B) digoxigenin-labeled antisense RNA. The sizes of markers are shown on the left and those of the transcripts detected are shown on the right.

Analysis of the cDNA sequences, which have been deposited in DDBJ/EMBL/GenBank under the accession numbers AB054992 (pex-1) and AB010968 (pex-6), revealed that the ORF of pex-6 was identical to f39g3.7 but that of pex-1 was not identical to any ORF(s) predicted by the GENEFINDER program. The pex-I cDNA (and its ORF) was composed of 24 exons, encoded by a genomic region containing three ORFs, c11h1.4, c11h1.5, and c11h1.6 (Fig. 3). The region predicting c11h1.4, which consisted of 14 exons, encoded the first 15 exons of the pex-1 ORF, ten of which were shared with c11h1.4. The spacer region between c11h1.5 and c11h1.6 encoded the 16th and 17th exons of pex-1. Exons 18 through 24 were shared with c11h1.6, although the 18th exon was extended to the 5′ side by 10 nucleotides from the start codon of c11h1.6. There was no significant deviation from the splice-site consensus sequences with two exceptions of 5′ splice sites having AG/GC (instead of AG/GU) in the 6th and 15th introns, which were not recognized by the program. The ORF c11h1.5 that has a different orientation from the others was encompassed in the 15th intron. The pex-1 and pex-6 genes encoded proteins of 996 and 720 amino acid residues, respectively.
Fig. 3
Genomic organization of the pex-1 gene. The closed rectangles above the line, which indicates part of the genomic sequence cloned in the cosmid c11h1, are exons for three ORFs predicted by the GENEFINDER program. The names and orientation of the ORFs are as indicated. The rectangles below the line denote exons determined by the pex-1 cDNA sequence; closed rectangles indicate the translated region and open rectangles indicate the untranslated regions. The asterisks mark exons not correctly predicted. The numbers indicate the first and last exons as well as the 15th through 18th exons for pex-1.

Identification of PEX-1 and PEX-6
To identify the tentatively termed pex-1 and pex-6 genes as genuine peroxin genes, we compared their amino acid sequences with those of biologically established SF2 members of the AAA protein family because no pex mutants were available in C. elegans and the expression of PEX-1 in a pex1 mutant (strain MB328) of the yeast S. cerevisiae did not complement the mutation (data not shown). There were five pairs of SF2 sequences, which were confirmed to be peroxins by their mutant phenotype. Their sources and the number of amino acid residues in parentheses of Pex1p/PEX1 and Pex6p/PEX6 were: S. cerevisiae (1043, 1030) (Erdmann et al., 1991; Voorn-Brouwer et al., 1993), Pichia pastoris (1157, 1165) (Heyman et al., 1994; Spong and Subramani, 1993), Yarrowia lipolytica (1023, 1025) (Titorenko et al., 2000; Nuttley et al., 1994), Hansenula polymorpha (1074, 1135) (Kiel et al., 1999), and Homo sapiens (1283, 980) (Reuber et al., 1997; Ports-teffen et al., 1997; Yahraus et al., 1996). The sequence similarities, especially in the region outside the AAA cassettes, were moderate and C. elegans PEX-6 was smaller than the putative orthologs. We therefore compared the sequences of three motifs in the two AAA cassettes; Walker motifs A and B for nucleotide binding and SRH with unknown function (Fig. 4). The first AAA cassette was unique for SF2 proteins and the second located closest to the C-terminus was characteristic for all AAA proteins. PEX-1 and PEX-6 of C. elegance showed a high degree of similarity to respective five cognate proteins not only in the motif sequences but also in distances between the motifs. In addition to a considerable sequence similarity in the respective N-terminal region (data not shown), three crucial residues (Fig. 4, marked by asterisks) identified the C. elegans PEX-1 and PEX-6 as genuine orthologs of Pex1p/PEX1 and Pex6p/PEX6, respectively.
Fig. 4
Motifs in the first and second AAA cassettes. PEX-1 and PEX-6 (the DDBJ/EMBL/GenBank accession numbers are AB054992 and AB010968, respectively) of C. elegans (Cel) were aligned with the Pex1p/PEX1 and Pex6p/PEX6 orthologs, respectively and thereafter the AAA cassette regions were taken from the final alignments. The abbreviations of their sources and the accession numbers are: Ppa, P. pastoris ( Z36987 and Z22556); Yli, Y. lipolytica ( AF208231 and L23858); Sce, S. cerevisiae ( M58676 and L20789); Hpo, H. polymorpha ( AF129873 and AF129874); Hsa, H. sapiens ( AF030356 and U56602). The numbers on the left represent the position of the first amino acid residue and those in parentheses indicate the residue number present between the motifs. Similar residues present in four or more sequences are shaded gray, and then four or more identical residues among them are blackened. The asterisks denote residues that distinguish the Pex1p/PEX1 and Pex6p/PEX6 sequences. The consensus sequences for Walker motifs A and B as well as SRH are shown above the alignments; h and x represent hydrophobic residues and any amino acid residue, respectively.

Spatio-temporal pattern of gene expression
The mRNAs of both pex-1 and pex-6 were detectable throughout the life cycle of C. elegans (Fig. 5). The extent of expression relative to that of CeIF, which is a homolog of eucaryotic initiation factor 4A and was used as the control for equal sample loading (Krause, 1995), was higher at the larval stage L3 and lower at the young adult stage (YA) than the other stages: embryo (E), larvae (L1, L2 and L4), or egg-laying adult (EA). The developmental patterns of gene expression for pex-1 and pex-6 were apparently parallel to each other, though the results were semiquantitative because of their extremely low level of expression. The tissue distributions of the pex-1 and pex-6 mRNA were examined by whole-mount in situ hybridization using antisense RNA probes (Fig. 6, A and B). Specimen used was L4 larva because in younger larval stages the somatic cell division is not completed and mature cuticle at adult stages tends to reduce the accessibility of RNA probes. Both of these mRNAs were detected mainly in intestinal cells.
Fig. 5
Amounts of pex-1 and pex-6 mRNA at each developmental stage. Poly(A)-rich RNA (5 μg of each) from embryos (E), larvae (L1, L2, L3, and L4), young adults (YA) and egg-laying adults (EA) were assessed by northern blot analysis as in Fig. 2. The pex-1, pex-6, and CeIF mRNAs were detected with the appropriate probes.

Fig. 6
Expression of the pex-1 and pex-6 mRNA in situ. Fixed L4 larvae were probed with the digoxigenin-labeled antisense RNA of pex-1 (A) or pex-6 (B) or with the sense RNA of pex-1 (C) or pex-6 (D) and incubated with alkaline phosphatase-labeled sheep anti-(digoxigenin) Fab fragment. Alkaline phosphatase catalyzed the formation of a dark blue precipitate in cells containing the pex-1 or pex-6 mRNA.

DISCUSSION
The sequences of the pex-1 and pex-6 cDNAs did not contain any of the 22-nucleotide SL sequences, which are trans-spliced to the 5′ terminus of about 70% of mRNA species of C. elegans (Krause and Hirsh, 1987; Zorio et al., 1994). This raised misgivings about the completeness of the cDNA, especially for the short pex-6 cDNA. However, 5′ RACE procedures under a wide variety of conditions revealed no further 5′ sequence beyond those cloned in pEMB842 or in pEMB807. This result together with the coincidence of cDNA lengths (3391 nt for pex-1 and 2303 nt for pex-6) with apparent mRNA lengths (3.4 kb for pex-1 and 2.3 kb for pex-6) indicated that the composite cDNAs were full-length sequences.
Eight pex-1 exons out of 24 were not correctly predicted by the GENEFINDER program (Fig. 3, marked by asterisked). This results from two unique features of the gene: a long intron and a biased codon usage. The unusually long 15th intron (3698 nt) misled into the split of the single pex-1 ORF into two ORFs c11h1.4 and c11h1.6 and missed the 16th and 17th exons and a part of the 18th exon. The incorrect prediction in the 5′ half of the pex-1 ORF may be due to the extremely low level of expression and an irregular codon usage. The prediction of ORF depends not only on splice site sequences but also on codon usage. Since codon usage in C. elegans varies among genes in a manner correlated with their expression level (Sharp and Bradnam, 1997), an extreme expression level and deviation from regular codon usage affect the prediction. The pex-1 ORF, indeed, shows more deviation (e.g., high frequency of GUG, UCG, ACA, and CAC) than the pex-6 ORF, which is correctly predicted.
The intestinal expression of pex-1 and pex-6 is similar to that of P-44, which is C. elegans type-II 3-oxoacyl-CoA thiolase involving in β-oxidation of acyl-compounds with an α-methyl branched-chain (Bun-ya et al., 1997, 1998). Since P-44 is present exclusively in peroxisomes (Maebuchi et al., 1999), the expression of pex-1 and pex-6 is consistent with their function as peroxins and suggests that the multifunctional intestinal cells of this organism also serve hepatic functions, for which peroxisomes are essential.
Many lines of evidence indicate that the interaction between Pex1p/PEX1 and Pex6p/PEX6 is required for peroxisome biogenesis (Tamura et al., 1998; Geisbrecht et al., 1998; Faber et al., 1998; Kiel et al., 1999). The homo-hexamers of each protein could constitute a heterogeneous double ring structure similar to that of N-ethylmaleimide-sensitive factor (NSF) because the AAA module tends to form a hexameric structure (Lenzen et al., 1998; Vale, 2000). In this context, it is notable that the expression patterns of pex-1 and pex-6 mRNAs were apparently parallel to each other (Fig. 5). Their synthesis may be co-regulated to keep the amounts of component proteins equivalent. It is plausible that the final multiprotein structure has influenced the molecular evolution of component proteins. Four pairs of yeast Pex1p and Pex6p are similar to each other in molecular size (S. cerevisiae, 1043 residues and 1030 residues; P. pastoris, 1157 and 1165; Y. lipolytica, 1023 and1025; H. polymorpha, 1074 and 1135), while PEX6 from the animal kingdom are smaller than PEX-1 by about 300 residues (x, 1283 and 980; C. elegans, 996 and 720). The moderate sequence similarities in the N-terminal region outside the AAA cassettes among each protein group suggest that this region evolved to fit the surface of the partner peroxin.
Acknowledgments
We thank Dr. Alan Coulson for his kind gift of the cDNA library of C. elegans. This work was supported in part by grants from the Ministry of Education, Science and Culture of Japan (03044104, 08780680, and 11876026).